

Introduction
In this article, you will see how to read text from image invoices using Python programming language. Text invoices contain variety of information such as product names, VAT, product prices, vendor or customer names, tax information, the date of the transaction etc. The process of reading text from images is called Object Character Recognition since characters in images are essentially treated as objects. Traditional computer vision as well as advanced deep learning approaches exist for OCR. Both the approaches have their own pros and cons. The article will briefly review both the approaches and will also discuss some of the challenges that are associated with invoice image recognition. Finally, you will see how to read text from a very simple invoice image using Tesseract library.
Prerequisites
- It is assumed that the readers have intermediate knowledge of the Python programming language since the code samples are in Python.
- Basic understanding of image processing will also help but is not required.
Approaches for OCR
As discussed earlier, approaches for object character recognition can be divided into two categories: Classic Computer Vision Based Approaches, and Advanced Deep Learning based approaches.
Classic Computer Vision Approach
The process adopted by classic computer vision based approaches for OCR can be divided into the following steps:
- Different type of filters are applied that normally blur the background, thus making the text more prominent and easier to identify.
- Text characters are recognized one by one in a sequence.
- Classification approaches are applied to classify the characters.
To further study about classification computer vision approaches. Checkout, these links.
Deep Learning Approaches
The deep learning based approaches use image recognition techniques along with the advanced neural networks to identify text from images. For instance, convolutional neural networks work best for image recognition hence they can be used to recognize text from images. Recurrent neural networks learn from sequence of data. therefore, they can be used to predict the next character which can help in the correction of mistakes. Also, RNN can help in parts of speech tagging and named entity recognition of the text, which can in turn help to identify whether the text is a product, currency, date etc.
Challenges Associated with Reading Invoice Images
As with any other OCR task, various challenges are associated with reading text from text invoices. Some of these challenges are enlisted below:
- Varying Text Density: The text in image invoices differ from image to image. Invoices with high text density are easier to read compared to low text density.
- Invoice Orientation: The orientation of invoices in the images is not same. Invoices with tilted oriented are difficult to read.
- Lack of Uniformity: Invoices differ a lot with the respect to the contents. For instance some invoices contain information about a customer's bank statement while the other invoices contain information about a particular transaction at a super market. The lack of uniformity among the fields in different invoices makes it extremely difficult to develop a universal invoice reader.
- Fonts and Character Differences: Fonts and character difference also adds to the difficulty in reading text from invoice images.
- Text Structure: Difference invoices have text located at different locations. For instance, in one invoice, the total amount may be at the top of the invoice with the prices of individual items broken down at the bottom. On the contrary, the other invoice may contain total amount at the bottom.
In short invoices come in all sizes and shapes and therefore, it is extremely challenging to develop a universal invoice image reader.
In the next section we will show a very crude approach to read invoice images using Python.
Reading Invoice Images with Python
The task of reading text from invoice images can be broadly categorized into two steps:
- Reading text from images
- Annotating text with correct labels.
Step1: Reading Text
The task of reading text from images is not limited to invoices. For instance, the applications exists which convert the hardcopy of textbooks into pdf and word format. Several Python libraries exist for reading text from images. However, we will be using Tesseract which is one of the most commonly used OCR libraries for Python.
The installation steps for the Tesseract library are as follows:
- Download the installation files for Tesseract from this link: https://github.com/UB-Mannheim/tesseract/wiki
- Install the corresponding files for your operating and remember the installation path.
- Execute the following command to install the Python wrapper for Tesseract:
$ pip install pytesseract
- The final step is to add the installation path in your Python script before you make any call to the Tesseract library function. For instance, for windows if your installation path is :C:\Program Files\Tesseract-OCR\, you will need to add the following script to your Python script before calling Tesseract functions:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
Let's now see how we can read text from Image Invoices using Tesseract. We will try to read text from the following invoice image:
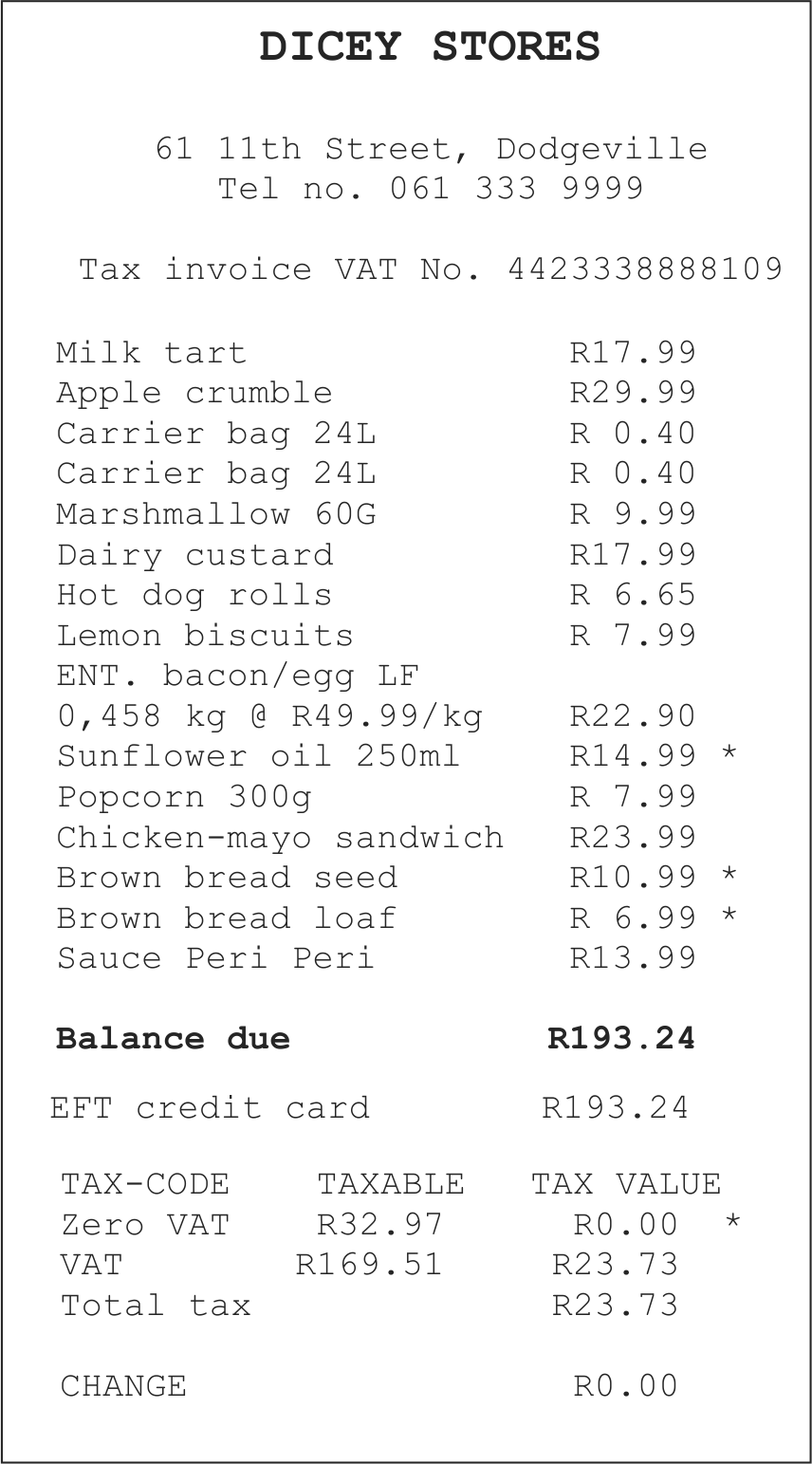
Look at the following script:
# import the necessary packages
from PIL import Image
import pytesseract
import argparse
import cv2
import os
import imutils
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
img = Image.open(r"E:\invoice2.jpeg")
text = pytesseract.image_to_string(img)
print(text)
In the script above we first loaded the image using the Image.open() function of the PIL (Python Imaging Library) module. The img object is then passed to the image_to_string() function of the pytesseract module which returns the text contents of the image. The text is then printed on the console.
Output:
DICEY STORES
61 11th Street, Dodgeville
Tel no. 061 333 9999
Tax invoice VAT No. 4423338888109
Milk tart R17.99
Apple crumble R29.99
Carrier bag 24L R 0.40
Carrier bag 24L R 0.40
Marshmallow 60G R 9.99
Dairy custard 17.99
Hot dog rolls 65
Lemon biscuits 99
ENT. bacon/egg LF
0,458 kg @ R49.99/kg R22.90
Sunflower oil 250ml R14.99
Popcorn 300g R 7.99
Chicken-mayo sandwich R23.99
Brown bread seed R10.99
Brown bread loaf R 6.99
Sauce Peri Peri R13.99
R
R
Balance due R193.24
EFT credit card R193.24
TAX-CODE TAXABLE TAX VALUE
Zero VAT R32.97 RO.OO *
VAT R169.51 R23.73
Total tax R23.73
CHANGE RO.00
You can see that the text has been read successfully since the text in the invoice was pretty clear and the invoice was not distorted. The formatting of the invoice further made it easier to read. We have read the text, the next step is to see how we can actually annotate the text.
Step2: Annotating Text
Annotating the data from a invoice is not as straight forward as it may seem. The domain knowledge plays a very important role in this regard. For instance, we want to know what type of data we want to annotate and how that data is presented in the invoice. For instance, in the invoice that we just read we know that each line contains a product name on the left and the price on the right.
Again it all depends upon what you need to extract from the invoice. Suppose we are only interested in the product names and their prices along with the total balance. Depending upon the format of the invoice, there are several ways to parse such information. We will see a very simple approach where we will iterate line by line through the text, tokenize the text to words and then read the product names and their corresponding prices.
We know that price occurs at the end of the line, therefore the last element of the tokenized line will be added to the Price column of the pandas datafram and the remaining words will be concatenated together and inserted in the Product_Name column. Let's first create a pandas dataframe with these two columns:
import pandas as pd
dataset = pd.DataFrame(columns=['Product_Name','Price'])
The script that iterates through the invoice text and then inserts the records into the dataframe is as follows:
from nltk.tokenize import word_tokenize
for i, line in enumerate(text.splitlines()):
if i < 7:
continue
word_list = word_tokenize(line)
if len(word_list) > 1 and any(i.isdigit() for i in word_list[-1]):
item_words = word_list[:-1]
if item_words[-1] == 'R':
item_words = item_words[:-1]
item = ' '.join(item_words)
price = word_list[-1]
if price[0] != 'R':
price = 'R' + price
dataset = dataset.append(pd.DataFrame([[item, price]], columns =dataset.columns))
In the script above, we start reading the text from the 7th line, since the record for the first product i.e. Milk tart occurs at the 7th line. We then tokenize each line via the word_tokenize method of the nltk.tokenize module. If the length of the tokenized list is not greater than one or the last item i.e. (price) doesn't contain any digit, the loop terminates. Else, if the second last item contains an 'R', the 'R' is removed and the remaining items are concatenated together and stored in the item variable. The last item is stored in the price variable. If the value of the price variable doesn't start with an R, it is appended at the beginning of the word. The item and price variables are then added to the dataset dataframe.
The dataset dataframe now contains products and their corresponding prices as shown below:

The output shows the image of the output pandas dataframe. There are afew problems with the output, for the product ENT.bacon/egg LF, only the second line is stored since the first line doesn't contain any integer value. However, these issues can be solved with regular expressions. The idea of this post is to demonstrate one of the possible approaches for reading invoiced via Python.
Conclusion
Extracting information from image invoices can be very useful for data mining in scenarios where digital invoices are not available. This article briefly explains how to extract text data from image invoices using Python Tesseract library. The article also discuses several approaches for OCR and different challenges in this domain.



